 Clickhouse-分片集群
Clickhouse-分片集群
[toc]
# 介绍
副本虽然能够提高数据的可用性,降低丢失风险,但是每台服务器实际上必须容纳全量数据,对数据的横向扩容没有解决。
要解决数据水平切分的问题,需要引入分片的概念。通过分片把一份完整的数据进行切分,不同的分片分布到不同的节点上,再通过 Distributed 表引擎把数据拼接起来一同使用。
Distributed 表引擎本身不存储数据,有点类似于 MyCat 之于 MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据。
注意:ClickHouse 的集群是表级别的,实际企业中,大部分做了高可用,但是没有用分片,避免降低查询性能以及操作集群的复杂性。
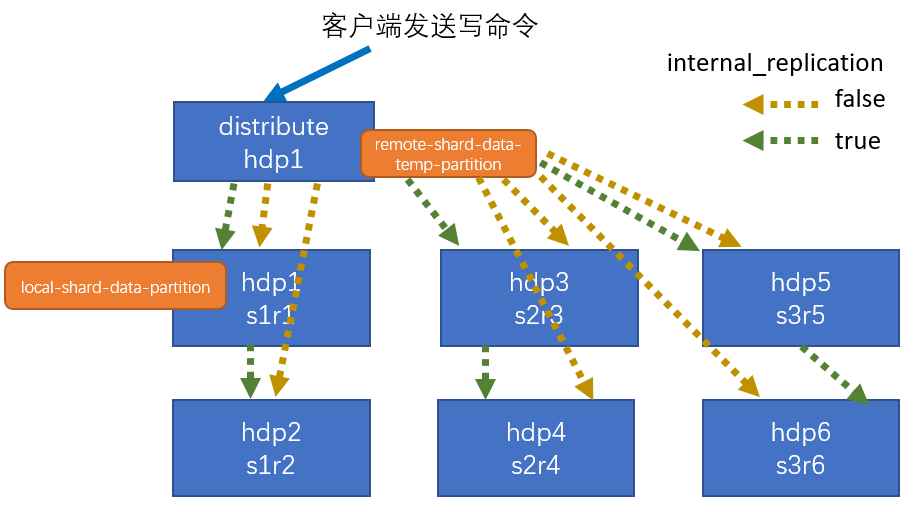
# 集群写入流程(3分片2副本共6个节点)
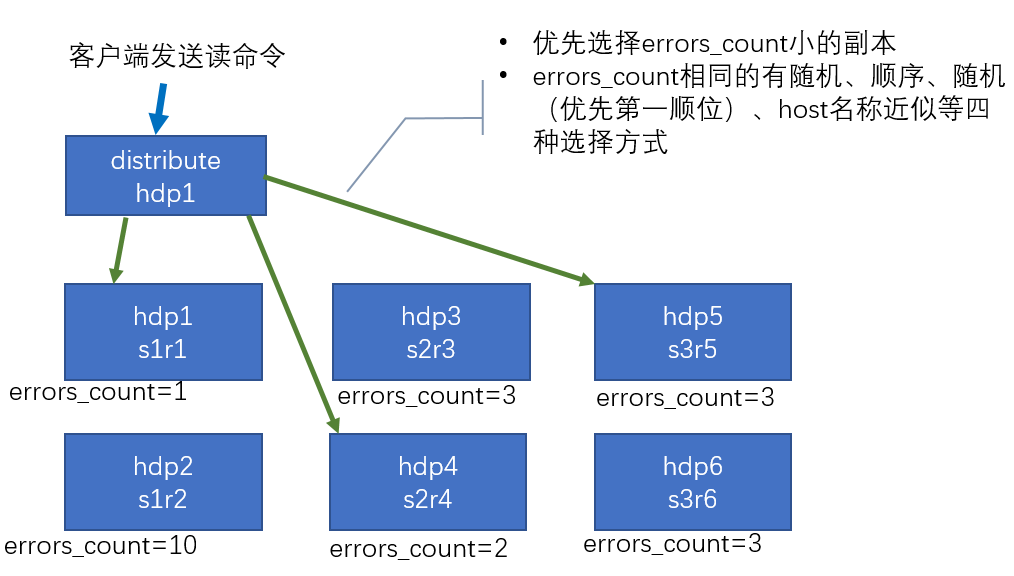
# 集群读取流程(3 分片 2 副本共 6 个节点)
# 3 分片 2 副本共 6 个节点集群配置
方法1:
外置配置文件配置
配置的位置还是在之前的/etc/clickhouse-server/config.d/metrika.xml,内容如下
<?xml version="1.0"?>
<yandex>
<remote_servers>
<gmall_cluster>
<!-- 集群名称-->
<shard>
<!--集群的第一个分片-->
<internal_replication>true</internal_replication>
<!--该分片的第一个副本-->
<replica>
<host>hadoop101</host>
<port>9000</port>
</replica>
<!--该分片的第二个副本-->
<replica>
<host>hadoop102</host>
<port>9000</port>
</replica>
</shard>
<shard>
<!--集群的第二个分片-->
<internal_replication>true</internal_replication>
<replica>
<!--该分片的第一个副本-->
<host>hadoop103</host>
<port>9000</port>
</replica>
<replica>
<!--该分片的第二个副本-->
<host>hadoop104</host>
<port>9000</port>
</replica>
</shard>
<shard>
<!--集群的第三个分片-->
<internal_replication>true</internal_replication>
<replica>
<!--该分片的第一个副本-->
<host>hadoop105</host>
<port>9000</port>
</replica>
<replica>
<!--该分片的第二个副本-->
<host>hadoop106</host>
<port>9000</port>
</replica>
</shard>
</gmall_cluster>
</remote_servers>
</yandex>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
方法二:
直接在config.xml中新增
<remote_servers>
<gmall_cluster>
<!-- 集群名称-->
<shard>
<!--集群的第一个分片-->
<internal_replication>true</internal_replication>
<!--该分片的第一个副本-->
<replica>
<host>hadoop101</host>
<port>9000</port>
</replica>
<!--该分片的第二个副本-->
<replica>
<host>hadoop102</host>
<port>9000</port>
</replica>
</shard>
<shard>
<!--集群的第二个分片-->
<internal_replication>true</internal_replication>
<replica>
<!--该分片的第一个副本-->
<host>hadoop103</host>
<port>9000</port>
</replica>
<replica>
<!--该分片的第二个副本-->
<host>hadoop104</host>
<port>9000</port>
</replica>
</shard>
<shard>
<!--集群的第三个分片-->
<internal_replication>true</internal_replication>
<replica>
<!--该分片的第一个副本-->
<host>hadoop105</host>
<port>9000</port>
</replica>
<replica>
<!--该分片的第二个副本-->
<host>hadoop106</host>
<port>9000</port>
</replica>
</shard>
</gmall_cluster>
</remote_servers>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 集群有密码需要添加配置认证
- 在每一个
replica下添加user,password配置,否则集群表无法查询,集群表数据之间无法正常同步
<shard>
<!--集群的第一个分片-->
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<!--该分片的第一个副本-->
<host>172.16.24.188</host>
<port>9000</port>
<user>default</user>
<password>o0iyoL35#DnNpucqv</password>
<password_sha256_hex>5a1a3048757d518b58c5578a315f76532df1701d1aed29d252de88734c432e52</password_sha256_hex>
</replica>
<replica>
<!--该分片的第二个副本-->
<host>172.16.24.190</host>
<port>9000</port>
<user>default</user>
<password>o0iyoL35#DnNpucqv</password>
<password_sha256_hex>5a1a3048757d518b58c5578a315f76532df1701d1aed29d252de88734c432e52</password_sha256_hex>
</replica>
</shard>
<shard>
<!--集群的第二个分片-->
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<!--该分片的第一个副本-->
<host>172.16.24.189</host>
<port>9000</port>
<user>default</user>
<password_sha256_hex>5a1a3048757d518b58c5578a315f76532df1701d1aed29d252de88734c432e52</password_sha256_hex>
<password>o0iyoL35#DnNpucqv</password>
</replica>
</shard>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 配置三节点版本集群及副本
# 集群及副本规划(2 个分片,只有第一个分片有副本)
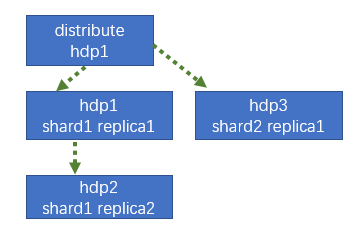
# 配置分片集群
1)方法1:在Clichouse的/etc/clickhouse-server/config.d 目录下创建 metrika-shard.xml 文件
注:也可以不创建外部文件,直接在 config.xml 的<remote_servers>中指定
<?xml version="1.0"?>
<yandex>
<remote_servers>
<ck_cluster_1>
<!-- 集群名称-->
<shard>
<!--集群的第一个分片-->
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<!--该分片的第一个副本-->
<host>172.16.24.174</host>
<port>9000</port>
</replica>
<replica>
<!--该分片的第二个副本-->
<host>172.16.24.175</host>
<port>9000</port>
</replica>
</shard>
<shard>
<!--集群的第二个分片-->
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<!--该分片的第一个副本-->
<host>172.16.24.176</host>
<port>9000</port>
</replica>
</shard>
</ck_cluster_1>
</remote_servers>
<zookeeper-servers>
<node index="1">
<host>172.16.24.174</host>
<port>2181</port>
</node>
<node index="2">
<host>172.16.24.175</host>
<port>2181</port>
</node>
<node index="3">
<host>172.16.24.176</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<shard>01</shard>
<!--不同机器放的分片数不一样-->
<replica>rep_1_1</replica>
<!--不同机器放的副本数不一样-->
</macros>
</yandex>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
ck_cluster集群标识,可以自行规定,在创建分布式表(引擎为Distributed)时需要用到。weight每个分片的写入权重值,数据写入时会有较大概率落到weight值较大的分片,这里全部设为1。internal_replication是否启用内部复制,即写入数据时只写入到一个副本,其他副本的同步工作靠复制表和ZooKeeper异步进行。
1)方法2:在Clichouse的/etc/clickhouse-server/config.xml文件修改
<remote_servers>
<ck_cluster_1>
<!-- 集群名称-->
<shard>
<!--集群的第一个分片-->
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<!--该分片的第一个副本-->
<host>172.16.24.174</host>
<port>9000</port>
</replica>
<replica>
<!--该分片的第二个副本-->
<host>172.16.24.175</host>
<port>9000</port>
</replica>
</shard>
<shard>
<!--集群的第二个分片-->
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<!--该分片的第一个副本-->
<host>172.16.24.176</host>
<port>9000</port>
</replica>
</shard>
</ck_cluster_1>
</remote_servers>
<zookeeper>
<node index="1">
<host>172.16.24.174</host>
<port>2181</port>
</node>
<node index="2">
<host>172.16.24.175</host>
<port>2181</port>
</node>
<node index="3">
<host>172.16.24.176</host>
<port>2181</port>
</node>
</zookeeper>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
ck_cluster集群标识,可以自行规定,在创建分布式表(引擎为Distributed)时需要用到。weight每个分片的写入权重值,数据写入时会有较大概率落到weight值较大的分片,这里全部设为1。internal_replication是否启用内部复制,即写入数据时只写入到一个副本,其他副本的同步工作靠复制表和ZooKeeper异步进行。
# 配置macros
macros 相当于是每个cliclhouse的环境变量。定义macros的作用在于可以用同一个包含macros变量的 SQL在所有的 clickhouse-server节点上执行。
注意:每台节点要配置自己的参数
<!-- 第一台机器 -->
<macros>
<shard>01</shard>
<replica>rep_1_1</replica>
</macros>
<!-- 第二台机器 -->
<macros>
<shard>01</shard>
<replica>rep_1_2</replica>
</macros>
<!-- 第三台机器-->
<macros>
<shard>02</shard>
<replica>rep_2_1</replica>
</macros>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
命名规则(建议)
shard:分片名称 01,02 ,03 ...
replica:rep_1_2 ; 1 分片id,2机器id
应用:
创建集群表时指定 ${shard}与${replica},执行时活自动获取到上面配置的值
create table st_order_mt on cluster ck_cluster_1 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine = ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
2
3
4
5
6
7
8
9
# 重启Clickhouse服务
clickhouse restart
# 验证
➢ 会自动同步到其他机器上
➢ 集群名字要和配置文件中的一致
➢ 分片和副本名称从配置文件的宏定义中获取
# 创建本地表
create table st_order_mt on cluster ck_cluster_1 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine
=ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
2
3
4
5
6
7
8
9
10
执行返回结果
:) create table st_order_mt on cluster ck_cluster_1 (
:-] id UInt32,
:-] sku_id String,
:-] total_amount Decimal(16,2),
:-] create_time Datetime
:-] ) engine
:-] =ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}')
:-] partition by toYYYYMMDD(create_time)
:-] primary key (id)
:-] order by (id,sku_id);
CREATE TABLE st_order_mt ON CLUSTER ck_cluster_1
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` Datetime
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt', '{replica}')
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id)
Query id: 722c5f5e-53d7-4283-ac30-e3aafb896198
┌─host──────────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ 172.16.24.174 │ 9000 │ 0 │ │ 2 │ 0 │
│ 172.16.24.175 │ 9000 │ 0 │ │ 1 │ 0 │
│ 172.16.24.176 │ 9000 │ 0 │ │ 0 │ 0 │
└───────────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
3 rows in set. Elapsed: 0.320 sec.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
提示在我们配置ck_cluster_1集群的节点上都创建成功了,分别在另外两台机器查询确认是否创建成功。
show tables;
# 创建 Distribute 分布式表
create table st_order_mt_d on cluster ck_cluster_1
(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
)engine = Distributed(ck_cluster_1,default, st_order_mt,hiveHash(sku_id));
2
3
4
5
6
7
参数含义: Distributed(集群名称,库名,本地表名,分片键)
分片键必须是整型数字,所以用 hiveHash 函数转换,也可以 rand()
- cluster:集群名称,在对分布式表执⾏读写的过程中,它会使⽤集群的配置信息来找到相应的host节点。
- database,table:数据库和本地表名称,用于将分布式表映射到本地表上。
- sharding_key: 分⽚键,分布式表会按照这个规则,将数据分发到各个本地表中。
# 插入数据
insert into st_order_mt_d values
(201,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(202,'sku_002',2000.00,'2020-06-01 12:00:00'),
(203,'sku_004',2500.00,'2020-06-01 12:00:00'),
(204,'sku_002',2000.00,'2020-06-01 12:00:00'),
(205,'sku_003',600.00,'2020-06-02 12:00:00');
2
3
4
5
6
# 查询分布式表
所有插入数据都可以查到
SELECT *
FROM st_order_mt_d
Query id: cddbd244-b165-4098-9184-83898286b1b7
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 202 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │
│ 203 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │
│ 204 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 205 │ sku_003 │ 600.00 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 201 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 在三台服务器分别查询本地表
只能查询到自己当前机器存储的数据
:) select * from st_order_mt;
SELECT *
FROM st_order_mt
Query id: aa19d289-28ba-4547-8675-609f4512e4e9
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 202 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │
│ 203 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │
│ 204 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
2
3
4
5
6
7
8
9
10
11
12
175 :) select * from st_order_mt;
SELECT *
FROM st_order_mt
Query id: 367fa862-289e-4c3e-98fe-7ef5bf6e7bb9
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 202 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │
│ 203 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │
│ 204 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
2
3
4
5
6
7
8
9
10
11
12
176 :) select * from st_order_mt;
SELECT *
FROM st_order_mt
Query id: 4c6a408e-7b5f-45c9-a6ee-e326da19dc53
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 205 │ sku_003 │ 600.00 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 201 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
2
3
4
5
6
7
8
9
10
11
12
13
我们的插入和查询任务都将使用分布式表,数据是分别保存本地表中的,分布式表是代理或映射关系 并不保存数据。可以理解分布式表是nginx,负责将读写任务分发到本地表。
如果要彻底删除分布表,则需要分别删除分布式表和本地表,其语法规则如下
--删除分布式表 DROP TABLE if exists test_log_all ON CLUSTER ck_cluster sync --删除本地表 DROP TABLE if exists test_log ON CLUSTER ck_cluster sync1
2
3
4
# 总结
插入和查询任务都将使用分布式表,数据是分别保存本地表中的,分布式表是代理或映射关系 并不保存数据。可以理解分布式表是nginx,负责将读写任务分发到本地表。
如果要彻底删除分布表,则需要分别删除分布式表和本地表,其语法规则如下
--删除分布式表 DROP TABLE if exists test_log_all ON CLUSTER ck_cluster sync --删除本地表 DROP TABLE if exists test_log ON CLUSTER ck_cluster sync1
2
3
4使用on cluster语句在集群的某台机器上执行以下代码,即可在每台机器上创建本地表和分布式表,其中⼀张本地表对应着⼀个数据分⽚,分布式表通常以本地表加“_all”命名。它与本地表形成⼀对多的映射关系,之后可以通过分布式表代理操作多张本地表。
这里有个要注意的点,就是分布式表的表结构尽量和本地表的结构一致。如果不一致,在建表时不会报错,但在查询或者插入时可能会抛出异常。
在集群中使用,我们要加上on cluster <cluster_name>的ddl,这样我们的建表语句在某一台clickhouse实例上执行一次即可分发到集群中所有实例上执行。
# SQL语句
# 创建本地表
create table st_order_mt on cluster ck_cluster_1 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine
=ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
2
3
4
5
6
7
8
9
10
说明:
{shard}与{replica}会读取配置文件中配置的macros值,如未配置,这两个值需要手动指定,这两个值每台服务器上要不同
# 创建 Distribute 分布式表
create table st_order_mt_d on cluster ck_cluster_1
(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
)engine = Distributed(ck_cluster_1,default, st_order_mt,hiveHash(sku_id));
2
3
4
5
6
7
说明:
Distributed(集群名称,库名,本地表名,分片键)
分片键必须是整型数字,所以用 hiveHash 函数转换,也可以 rand()
cluster:集群名称,在对分布式表执⾏读写的过程中,它会使⽤集群的配置信息来找到相应的host节点。
database,table:数据库和本地表名称,用于将分布式表映射到本地表上。
sharding_key: 分⽚键,分布式表会按照这个规则,将数据分发到各个本地表中。
# 删除分布式表
--删除分布式表
DROP TABLE if exists test_log_all ON CLUSTER ck_cluster sync
--删除本地表
DROP TABLE if exists test_log ON CLUSTER ck_cluster sync
2
3
4