 数据湖Iceberg-存储结构(2)
数据湖Iceberg-存储结构(2)
[toc]
数据湖Iceberg-简介(1) (opens new window) 数据湖Iceberg-存储结构(2) (opens new window) 数据湖Iceberg-Hive集成Iceberg(3) (opens new window) 数据湖Iceberg-SparkSQL集成(4) (opens new window) 数据湖Iceberg-FlinkSQL集成(5) (opens new window) 数据湖Iceberg-FlinkSQL-kafka类型表数据无法成功写入(6) (opens new window) 数据湖Iceberg-Flink DataFrame集成(7) (opens new window)
# 存储结构
# 数据文件 data files
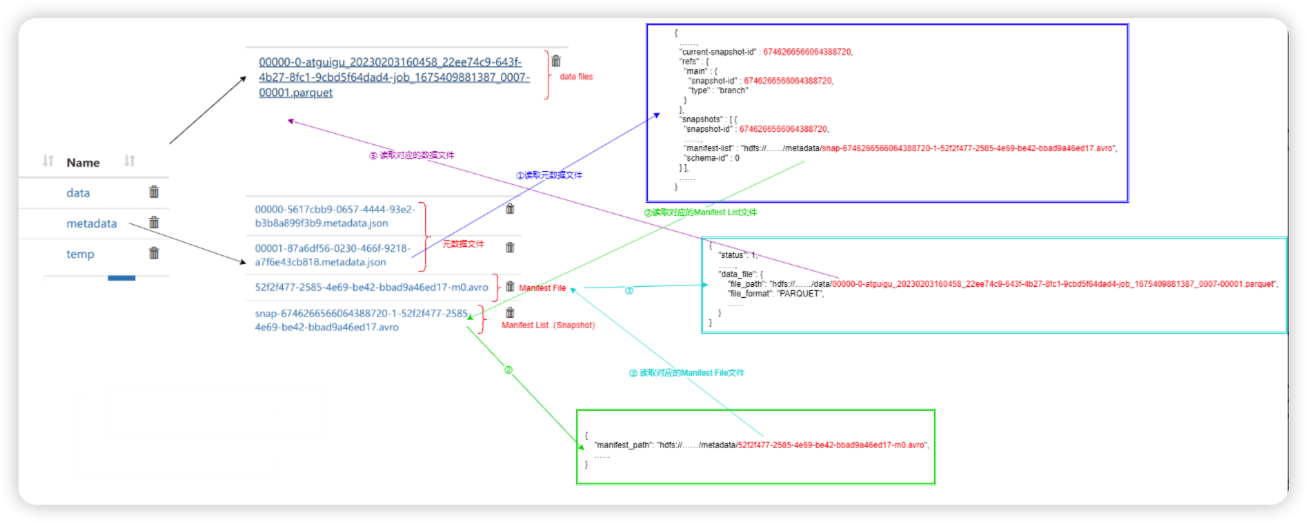
数据文件是Apache Iceberg表真实存储数据的文件,一般是在表的数据存储目录的data目录下,如果我们的文件格式选择的是parquet,那么文件是以“.parquet”结尾。
例如:00000-0-atguigu_20230203160458_22ee74c9-643f-4b27-8fc1-9cbd5f64dad4-job_1675409881387_0007-00001.parquet 就是一个数据文件。
Iceberg每次更新会产生多个数据文件(data files)。
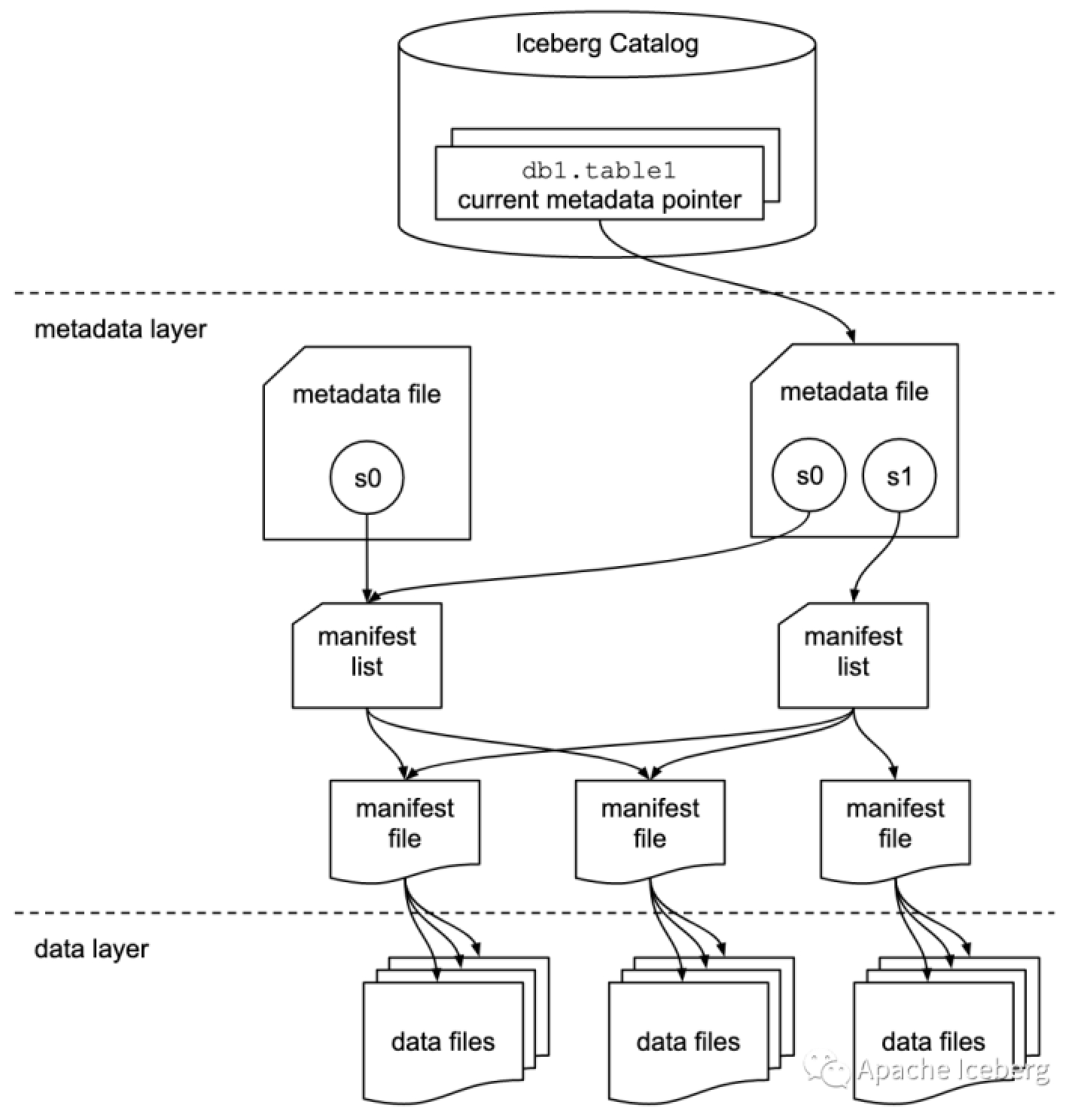
# 表快照 Snapshot
快照代表一张表在某个时刻的状态。每个快照里面会列出表在某个时刻的所有 data files 列表。data files是存储在不同的manifest files里面,manifest files是存储在一个Manifest list文件里面,而一个Manifest list文件代表一个快照。
# 清单列表 Manifest list
manifest list是一个元数据文件,它列出构建表快照(Snapshot)的清单(Manifest file)。这个元数据文件中存储的是Manifest file列表,每个Manifest file占据一行。每行中存储了Manifest file的路径、其存储的数据文件(data files)的分区范围,增加了几个数文件、删除了几个数据文件等信息,这些信息可以用来在查询时提供过滤,加快速度。
例如:snap-6746266566064388720-1-52f2f477-2585-4e69-be42-bbad9a46ed17.avro就是一个Manifest List文件。
# 清单文件 Manifest file
Manifest file也是一个元数据文件,它列出组成快照(snapshot)的数据文件(data files)的列表信息。每行都是每个数据文件的详细描述,包括数据文件的状态、文件路径、分区信息、列级别的统计信息(比如每列的最大最小值、空值数等)、文件的大小以及文件里面数据行数等信息。其中列级别的统计信息可以在扫描表数据时过滤掉不必要的文件。
Manifest file是以avro格式进行存储的,以“.avro”后缀结尾,例如:52f2f477-2585-4e69-be42-bbad9a46ed17-m0.avro。