 keyBy数据分配计算方法
keyBy数据分配计算方法
[toc]
# 场景
Flink keyBy是根据某一个字段Hash后除以6取余数,原以为每个subtask会平均处理数据量,结果发现没有相对平均处理。有三个subtask没有数据
# 问题
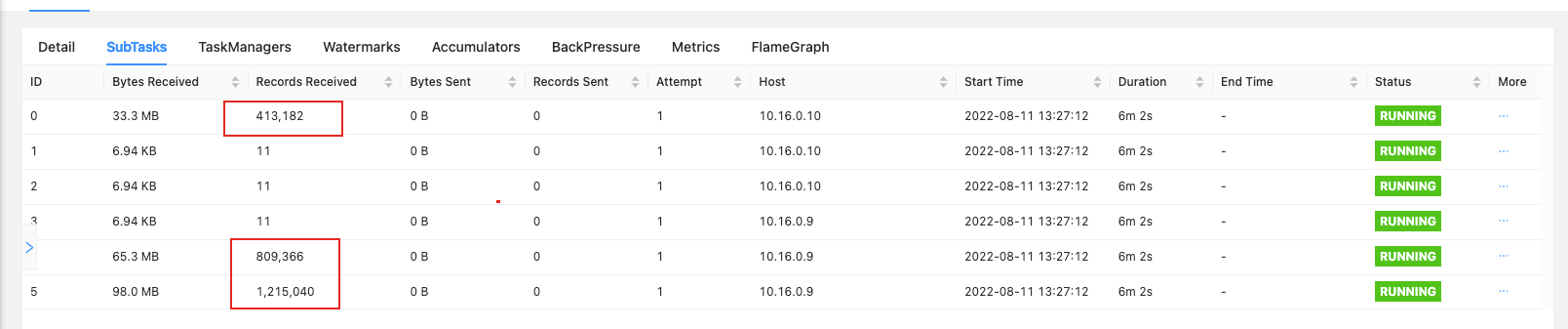
Flink代码keyBy后发现数据没有平均分配到每一个subtask中,数据分配比例大概为1,0,0,0,2,3 (六份数据),具体数据处理比例见下图
Records 为11,这11条数据是广播的数据,不是keyBy分配的数据
# 分析
查询资料发现keyBy分组的算法在 KeyGroupRangeAssignment类中assignKeyToParallelOperator方法
源码如下(仅列出部分需要的):
public static int assignKeyToParallelOperator(Object key, int maxParallelism, int parallelism) {
Preconditions.checkNotNull(key, "Assigned key must not be null!");
return computeOperatorIndexForKeyGroup(
maxParallelism, parallelism, assignToKeyGroup(key, maxParallelism));
}
public static int assignToKeyGroup(Object key, int maxParallelism) {
Preconditions.checkNotNull(key, "Assigned key must not be null!");
return computeKeyGroupForKeyHash(key.hashCode(), maxParallelism);
}
public static int computeKeyGroupForKeyHash(int keyHash, int maxParallelism) {
return MathUtils.murmurHash(keyHash) % maxParallelism;
}
public static int computeOperatorIndexForKeyGroup(
int maxParallelism, int parallelism, int keyGroupId) {
return keyGroupId * parallelism / maxParallelism;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
通过源码分析,计算方法为:(MathUtils.murmurHash(key.hashCode()) % maxParallelism) * parallelism / maxParallelism
接下来继续分析每一个值具体是多少。
- key
key不用说了就是我们keyBy的值
maxParallelism
计算默认最大并行度的方法
public static int computeDefaultMaxParallelism(int operatorParallelism) { checkParallelismPreconditions(operatorParallelism); return Math.min( Math.max( MathUtils.roundUpToPowerOfTwo( operatorParallelism + (operatorParallelism / 2)), DEFAULT_LOWER_BOUND_MAX_PARALLELISM), UPPER_BOUND_MAX_PARALLELISM); }1
2
3
4
5
6
7
8
9
10
11我们实际开的并行度只有6,最终计算出的
maxParallelism取值为DEFAULT_LOWER_BOUND_MAX_PARALLELISM = 1<<7即128parallelism
我们自己设置的6
# 编写代码模拟分配
int maxParallelism = 1<<7;
// i keyBy字段,代码中keyBy也使用的int类型
for (int i = 0; i < 6; i++) {
//注意这里要转为Object,与源码中方法相同
Object key = i;
// 代码中并行度
int parallelism = 6;
int keyGroupId = MathUtils.murmurHash(key.hashCode()) % maxParallelism;
int index = keyGroupId * parallelism / maxParallelism;
System.out.println("数据分配:"+index);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
分配结果
数据分配:4
数据分配:4
数据分配:5
数据分配:5
数据分配:0
数据分配:5
1
2
3
4
5
6
2
3
4
5
6
# 验证
通过上面我们模拟计算的结果,发现数据分配至为0->1/5数据,4->2/5数据,5->3/5数据,与Flink中查看处理数据量比例相同。
# 解决
既然知道计算方法,我们就按照算法进行数据平均分配,将keyBy的值进行相对应修改即可。
上次更新: 2023/03/10, 16:57:29